0. 介绍
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
- Java语言实现的开源框架;
- 使用简单模型处理大量数据;
- 集群、分布式处理;
- 计算、存储、高可靠;
- 核心组件(狭义上的Hadoop):
- HDFS:分布式文件存储系统;
- YARN:作业调度和集群资源管理框架,解决资源任务调度;
- MAPREDUCE:分布式运算编程框架,解决海量数据计算;
- 特点:
- 扩容能力:集群;
- 成本低:单个机子要求并不高;
- 高效率:分布式,支持并发的数据处理;
- 可靠性:备份、副本,任务失败后重新执行等;
- 集群:
Hadoop集群具体来说包含两个集群:HDFS集群和YARN集群,二者逻辑上分离,物理上常在一起。
- HDFS集群:负责海量数据的存储;
- NameNode
- DataNode
- SecondaryNameNode
- YARN集群:负责海量数据运算时的资源调度;
- ResourceManager
- NodeManager
说明:mapreduce是一个分布式运算编程框架,是应用程序开发包,由用户安装规范进行程序开发后打包运行在HDFS集群上,并且收到YARN集群的资源调度管理。
1. 集群搭建
1.1 准备:
-
系统:ubuntu 16.04 x 3(时间统一;防火墙关闭);
- 网络及免密配置:参考ubuntu ssh免密配置;
-
jdk安装:参考ubuntu下jdk安装;
- 部署说明:
- node-1:NameNode、DataNode、ResourceManager;
- node-2:DataNode、NodeManager、SecondaryNameNode;
- node-3:DataNode、NodeManager;
1.2 下载Hadoop:
1.3 解压(node-1):
$: tar -zxvf 'hadoop-3.2.1.tar.gz' -C ~/
1.4 配置(./hadoop-3.2.1/etc/hadoop/):
-
hadoop-env.sh:
export JAVA_HOME=/usr/local/jdk1.8.0_91 -
core-site.xml:
<!-- 指定Hadoop所使用的文件系统schema(URI),HDFS的NameNode的地址--> <property> <name>fs.defaultFS</name> <value>hdfs://node-1:9000</value> </property> <!-- 指定运行中产生数据的存放目录 --> <property> <name>hadoop.tmp.dir</name> <value>/home/gp/hadoop-3.2.1/data/hdata</value> </property> -
hdfs-site.xml:
<!-- 指定HDFS副本的数量,默认3 --> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>node-2:50090</value> </property> -
mapred-site.xml:
<!-- 指定mr运行时框架,这里指定在yarn上,默认是local --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> -
yarn-site.xml:
<!-- 指定yarn的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>node-1</value> </property> <!-- NodeManager上运行的附属服务。需配置成mapredue_shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> -
slaves(从节点主机名,新版本改名为workers):
node-1 node-2 node-3 -
配置环境变量(/etc/profile):
export HADOOP_HOME=/home/gp/hadoop-3.2.1 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin -
刷新环境变量:
$: source /etc/profile说明:hadoop中一般自定义配置文件名称为**-site.xml,对于未自定义的配置,hadoop默认的**-default.xml都有默认值。
补充:终端执行
hadoop classpath,将返回值配置到yarn-site.xml中: -
yarn-site.xml:
<property> <name>yarn.application.classpath</name> <value>/home/gp/hadoop-3.2.1/etc/hadoop:/home/gp/hadoop-3.2.1/share/hadoop/common/lib/*:/home/gp/hadoop-3.2.1/share/hadoop/common/*:/home/gp/hadoop-3.2.1/share/hadoop/hdfs:/home/gp/hadoop-3.2.1/share/hadoop/hdfs/lib/*:/home/gp/hadoop-3.2.1/share/hadoop/hdfs/*:/home/gp/hadoop-3.2.1/share/hadoop/mapreduce/lib/*:/home/gp/hadoop-3.2.1/share/hadoop/mapreduce/*:/home/gp/hadoop-3.2.1/share/hadoop/yarn:/home/gp/hadoop-3.2.1/share/hadoop/yarn/lib/*:/home/gp/hadoop-3.2.1/share/hadoop/yarn/*</value> </property>
1.5 分发到node-2、node-3:
$ scp -r hadoop-3.2.1/ gp@node-2:~/
$ scp -r hadoop-3.2.1/ gp@node-3:~/
# node-2、node-3配置环境变量并刷新
2. 启动
启动集群需要启动HDFS和YARN两个集群。
注意:
-
首次启动HDFS时,必须对其进行初始化操作,因为此时HDFS在物理上还是不存在的。
- 初始化只在主节点执行一次;
- 格式化命令:
hdfs namenode -format或者hadoop namenode -format。
2.1 单节点逐个启动:
- 主节点启动/关闭NameNode:
hadoop-daemon.sh start/stop namenode; - 从节点启动/关闭DataNode:
hadoop-daemon.sh start/stop datanode; - 主节点启动/关闭ResourceManager:
yarn-daemon.sh start/stop resourcemanager; - 从节点启动/关闭NodeManager:
yarn-daemon.sh start/stop nodemanager;
2.2 一键启动:
需要配置workers和ssh免密。在主节点执行:
- hdfs:
${HADOOP_HOME}/sbin/start-dfs.sh/${HADOOP_HOME}/sbin/stop-dfs.sh; - yarn:
${HADOOP_HOME}/sbin/start-yarn.sh/${HADOOP_HOME}/sbin/stop-yarn.sh;
说明:通过jps命令可以查看启动状态。
gp@node-1:~/hadoop-3.2.1/sbin$ start-dfs.sh
Starting namenodes on [node-1]
node-1: WARNING: /home/gp/hadoop-3.2.1/logs does not exist. Creating.
Starting datanodes
node-3: WARNING: /home/gp/hadoop-3.2.1/logs does not exist. Creating.
node-2: WARNING: /home/gp/hadoop-3.2.1/logs does not exist. Creating.
Starting secondary namenodes [node-2]
gp@node-1:~/hadoop-3.2.1/sbin$ jps
2615 DataNode
2488 NameNode
2845 Jps
gp@node-1:~/hadoop-3.2.1/sbin$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
gp@node-1:~/hadoop-3.2.1/sbin$ jps
2615 DataNode
2488 NameNode
3786 Jps
3326 ResourceManager
3471 NodeManager
2.3 查看(node-1):
- hdfs:
http://node-1:9870; - yarn:
http://node-1:8088;
2.4 体验hdfs:
- 点击utils下的’Browse the file System’,可以看到初始没有任何文件:
- 命令行执行:
hdfs dfs -ls /,发现为空:
gp@node-1:~/software/hadoop-3.2.1/sbin$ hdfs dfs -ls /
gp@node-1:~/software/hadoop-3.2.1/sbin$
- 创建文件夹:
hdfs dfs -mkdir /hello,刷新页面,可以看到已生成:
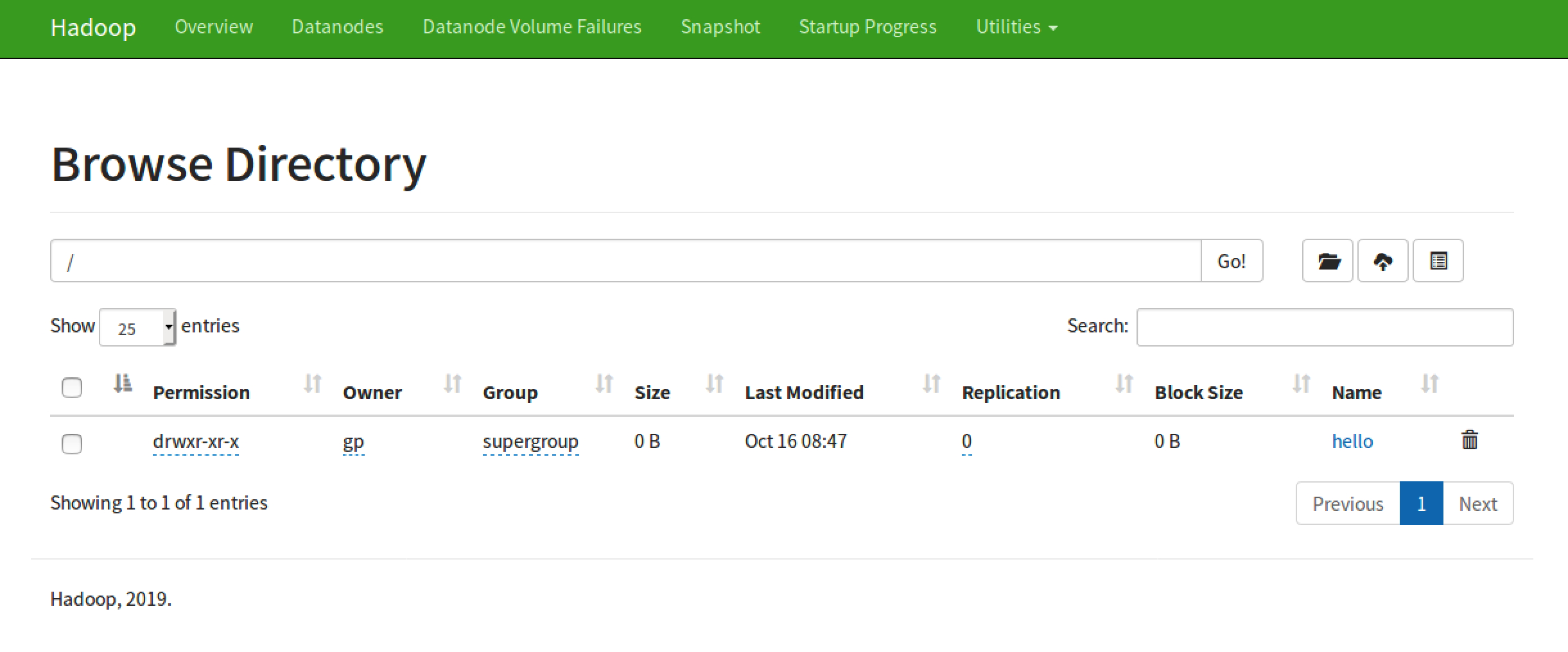
- 同样,执行命令也可以查看到:
gp@node-1:~/software/hadoop-3.2.1/sbin$ hdfs dfs -ls /
Found 1 items
drwxr-xr-x - gp supergroup 0 2019-10-16 08:47 /hello
gp@node-1:~/software/hadoop-3.2.1/sbin$ hdfs dfs -mkdir -p /tmp/input
- 上传文件:
hdfs dfs -put wordcount.txt /tmp/input;
This is a test
For word count
Hello world
Please sum the word For me
2.5 体验yarn(提交运行mapreduce程序)
- yarn首页:
-
在./hadoop-3.2.1/share/hadoop/mapreduce下官方自带测试程序hadoop-mapreduce-examples-3.2.1.jar,执行如下命令进行测试:
hadoop jar hadoop-mapreduce-examples-3.2.1.jar wordcount /tmp/input /tmp/output -
结果:
gp@node-1:~/hadoop-3.2.1/sbin$ hdfs dfs -cat /tmp/output/part-r-00000 2019-10-16 18:16:45,167 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false For 2 Hello 1 Please 1 a 1 count 1 is 1 me 1 s 1 sum 1 test 1 the 1 word 2 world 1
3. HDFS
3.1 概念:
- HDFS:Hadoop Distribute File System,Hadoop分布式文件系统。Hadoop核心组件之一,底层的分布式存储服务。
- NameNode:元数据管理。负责维护整个hdfs文件系统的目录结构,以及每个文件对应的block信息;
- DataNode:存储数据。定时向NameNode汇报自己存储的block信息;
注意:
- NameNode并不会持久化存储文件块在DataNode上的储存信息,这些信息会在服务启动时从数据节点重建(NameNode还有文件系统镜像和操作日志),因此一般NameNode所在机器需要较大内存;
- 客户的操作请求都是先由NameNode接收和处理的;
- DataNode在启动时会向NameNode上报自己存储的块信息等,且会跟NameNode维持心跳(默认3s)。块信息维持心跳默认间隔6小时;
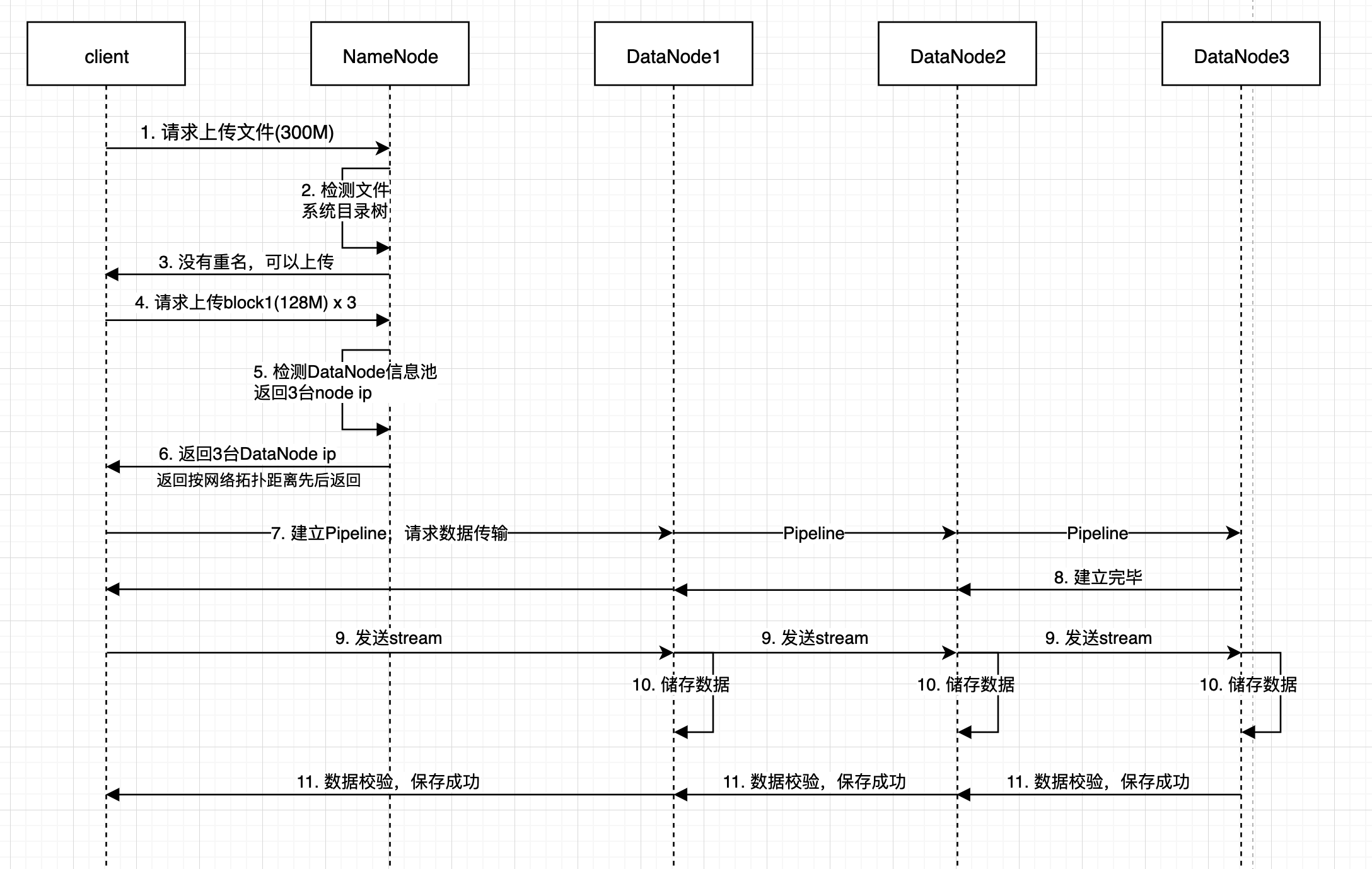
3.2 上传流程:
3.3 下载流程:
- 客户端向NameNode发起请求;
- NameNode按一定排序规则,视情况返回block的部分或全部列表,包含每个block的副本信息;
- 客户端优先从返回列表靠前的DataNode上获取数据;
- 建立Socket Stream,并行的读取block信息。若读取完列表的block信息,文件读取还没有完,则继续向NameNode获取下一批block信息;
- 每读取完一个block都会进行checksum验证,如果读取DataNode时出现错误,客户的会通知NameNode,然后再向下一个副本读取;
- 最终读取完的block会在客户的组成完整文件;
3.4 命令行操作:
hdfs命令操作不仅支持HDFS文件系统,还支持本地FS、HFTP FS、S3 FS等。URI格式为scheme://authrity/path。HDFS的scheme为hdfs,本地fs的scheme为file。scheme和authority是可选的,如果未指定,使用默认方案。示例:
hadoop fs -ls hdfs://node-1:9000/ # hdfs文件系统;hadoop fs -ls file:///root/ # 本地fs系统;
说明:hadoop fs <args> 和hdfs dfs <args>效果一样。前者为新版本中命令,推荐使用。
常用命令:
- -ls:参数-R表示递归展示,-h优化文件大小展示;
- -mkdir:-p表示多级创建;
- -put:-f表示覆盖同名文件;
- -get:-f同get;
- -appendToFile:追加到文件末尾;
- -cat:同cat;
- -tail:文件最后一千字节显示到stdout;
- -chgrp:修改组;
- -chmod:修改权限;
- -chown:修改拥有者;
- -copyFromLocal:同put;
- -copyToLocal:同get;
- -cp:复制;
- -mv:移动;
- -getmerge:合并。如:
hadoop fs -getmerge /aaa/log.* ./log.sum; - -rm:-r表示递归删除;
- -df:查看磁盘信息;
- -du:显示目录中所有文件大小;
- -setrep:改变副本个数。-R表示递归改变子文件:
hadoop fs -setrep -w 3 -R /tmp
3.5 应用开发(Java)
HDFS的应用开发一般就是通过提供的api构造客户端对象,进行文件操作。
- 引入pom依赖:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.1</version>
</dependency>
</dependencies>
- 使用到类:
-
Configuration:封装客户端或服务端的配置;
-
FileSystem:文件系统,操作文件,通过静态方法
get()获取对象:FileSystem fs = FileSystem.get(conf)该方法从conf中的一个参数fs.getDefaultFS的配置值判断具体是什么类型的文件系统。如果配置中没有指定该值,且classpath下没有相应配置,则该值使用hadoop的jar包中core-default.xml,默认值为file:///,此时获取的不是DistributedFileSystem的实例,而是一个本地文件系统的客户端对象。
- 代码:
package cn.adoredu.hdfs;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.FileInputStream;
import java.net.URI;
public class HDFSTestClient {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://node-1:9000");
// 设置客户的身份
// System.setProperty("HADOOP_USER_NAME", "gp");
FileSystem fs = FileSystem.get(conf);
// 也可以通过如下方式指定文件系统类型并且设置用户身份
// FileSystem fs = FileSystem.get(new URI("hdfs://node-1:9000"), conf, "gp");
// 创建一个目录
// fs.create(new Path("/helloByJava"));
// 下载文件
// fs.copyToLocalFile(new Path("/tmp/input/wordcount.txt"), new Path("/Users/gp/Desktop/tmp"));
// 下载后会在对应路径下有wordcount.txt和一个标识成功的.wordcount.txt.crc文件
// 流式操作,更底层的操作
// 将本地文件上传到hdfs
FSDataOutputStream outputStream = fs.create(new Path("/test.txt"), true);
FileInputStream inputStream = new FileInputStream("/Users/gp/Desktop/tmp/test.txt");
IOUtils.copy(inputStream, outputStream);
// 关闭连接
fs.close();
}
}
package cn.adoredu.hdfs;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.Before;
import org.junit.Test;
public class HdfsClient {
FileSystem fs = null;
@Before
public void init() throws Exception {
Configuration conf = new Configuration();
// conf.set("fs.defaultFS", "hdfs://node-1:9000");
/**
* 参数优先级: 1、客户端代码中设置的值 2、classpath下的用户自定义配置文件 3、然后是jar中默认配置
*/
// 获取一个hdfs的访问客户端
fs = FileSystem.get(new URI("hdfs://node-1:9000"), conf, "gp");
}
/**
* 往hdfs上传文件
*
* @throws Exception
*/
@Test
public void testAddFileToHdfs() throws Exception {
// 要上传的文件所在的本地路径
// 要上传到hdfs的目标路径
Path src = new Path("/tmp/test.txt");
Path dst = new Path("/");
fs.copyFromLocalFile(src, dst);
fs.close();
}
/**
* 从hdfs中复制文件到本地文件系统
*
* @throws IOException
* @throws IllegalArgumentException
*/
@Test
public void testDownloadFileToLocal() throws IllegalArgumentException, IOException {
// fs.copyToLocalFile(new Path("/test.txt"), new Path("/tmp"));
fs.copyToLocalFile(false, new Path("/test.txt"), new Path("/tmp"), true);
fs.close();
}
/**
* 目录操作
*
* @throws IllegalArgumentException
* @throws IOException
*/
@Test
public void testMkdirAndDeleteAndRename() throws IllegalArgumentException, IOException {
// 创建目录
fs.mkdirs(new Path("/a1/b1/c1"));
// 删除文件夹 ,如果是非空文件夹,参数2必须给值true
fs.delete(new Path("/aaa"), true);
// 重命名文件或文件夹
fs.rename(new Path("/a1"), new Path("/a2"));
}
/**
* 查看目录信息,只显示文件
*
* @throws IOException
* @throws IllegalArgumentException
* @throws FileNotFoundException
*/
@Test
public void testListFiles() throws FileNotFoundException, IllegalArgumentException, IOException {
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println(fileStatus.getPath().getName());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getLen());
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for (BlockLocation bl : blockLocations) {
System.out.println("block-length:" + bl.getLength() + "--" + "block-offset:" + bl.getOffset());
String[] hosts = bl.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
System.out.println("--------------打印的分割线--------------");
}
}
/**
* 查看文件及文件夹信息
*
* @throws IOException
* @throws IllegalArgumentException
* @throws FileNotFoundException
*/
@Test
public void testListAll() throws FileNotFoundException, IllegalArgumentException, IOException {
FileStatus[] listStatus = fs.listStatus(new Path("/"));
String flag = "";
for (FileStatus fstatus : listStatus) {
if (fstatus.isFile()) {
flag = "f-- ";
} else {
flag = "d-- ";
}
System.out.println(flag + fstatus.getPath().getName());
System.out.println(fstatus.getPermission());
}
}
}
代码位置:https://github.com/AdoredU/hadoop-demo。
4. MapReduce
4.1 思想
MapReduce是一种”分而治之”的设计思想,用于能够把复杂问题先简化为多个简单问题处理,再进行汇总的场景。
Map负责分,将复杂问题拆分为可以并行计算的小任务,要求各任务间几乎没有依赖关系。
Reduce负责合,即对map阶段的结果进行全局汇总。
以Hadoop中WordCount案例理解MapReduce:
如果要对文本进行单词统计,由于文件在hdfs中分布式存储,常规做法要将各文件下载至本地,通过编写java程序实现统计。这样实际上下载、整合文件本身就浪费资源,再加上要单线执行任务,效率会很低。
而使用MapReduce思想,可以在hdfs上每个对每个block文件先进行统计,可以理解为map映射,最后统一计算,即reduce全局汇总。
4.2 Hadoop中MapReduce
MapReduce是一个分布式运行程序的编程框架。核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在Hadoop 集群上。
###4.3 MapReduce框架结构(MapReduce2.0)
一个完整的mapreduce程序在分布式运行时有三类实例进程:
1、MRAppMaster:负责整个程序的过程调度及状态协调;
2、MapTask:负责map阶段的整个数据处理流程;
3、ReduceTask:负责reduce阶段的整个数据处理流程 ;
###4.4 编程规范
- 用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行 mr 程 序的客户端);
- Mapper 的输入数据是 KV 对的形式(KV 的类型可自定义);
-
Mapper 的输出数据是 KV 对的形式(KV 的类型可自定义) ;
- Mapper 中的业务逻辑写在 map()方法中;
- map()方法(maptask 进程)对每一个<K,V>调用一次;
- Reducer 的输入数据类型对应 Mapper 的输出数据类型,也是 KV ;
- Reducer 的业务逻辑写在 reduce()方法中;
- Reducetask 进程对每一组相同 k 的<k,v>组调用一次 reduce()方法;
- 用户自定义的 Mapper 和 Reducer 都要继承各自的父类;
- 整个程序需要一个 Drvier 来进行提交,提交的是一个描述了各种必要信 息的 job 对象
4.5 WordCount案例
依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.adoredu</groupId>
<artifactId>example-hdfs</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.8.2</version>
</dependency>
</dependencies>
</project>
Mapper类:
package cn.adoredu.mapreduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* MR程序mapper阶段的处理类:
*
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
* KEYIN:mapper数据输入的key类型,默认的数据读取组件会一行一行的读取数据,
* 读取一行返回一行。这里表示每一行的起始偏移量,数据类型为Long;
* VALUEIN:这里表示读取没一行的内容,数据类型为String;
* KEYOUT:本地输出的是单词,数据类型为String;
* VALUEOUT:本地为单词次数,数据类型为Integer;
*
* 注意,这里的数据类型都为jdk的自带类型,跨网络传输序列化时效率地下,因此hadoop封装了对应的数据类型:
* Long -> LongWritable;
* String -> Text;
* Integer -> Intwritable;
* null -> NullWritable
*
* Mapper生命周期方法:
* setup(): Called once at the beginning of the task
* cleanup(): Called once at the end of the task
* setup(): Called once for each key/value pair in the input split.
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
/**
* mapper阶段的业务逻辑实现方法。该方法的调用取决于读取数据组件有无给mr传入数据。
* 如果有,每传入一个kv对都调用一次。
* @param key
* @param value
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 拿到传入的一行内容,转化为String
String line = value.toString();
// 按照分隔符切割成单词数组
String[] words = line.split(" ");
// 遍历数组,每个单词标记1(整理交由reduce阶段)
for (String word : words) {
// 使用mr程序上下问context
// 把mapper阶段处理的数据发送作为reduce阶段的输入
context.write(new Text(word), new IntWritable(1));
}
}
}
Reducer类:
package cn.adoredu.mapreduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* MR程序reduce阶段的处理类:
*
* KEYIN:reduce阶段输入key类型,对应mapper阶段输出key类型,这里就是单词 Text;
* VALUEIN:reduce阶段输入value类型,对应mapper阶段输出value类型,这里是单词次数, IntWritable;
* KEYOUT:单词,Text;
* VALUEOUT:单词总次数,IntWritable;
*
* Reducer生命周期方法:与Mapper中类似。
*/
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* reduce接收所有来自mapper阶段的数据,按照key字典序排序。然后按照key是否相同调用reduce方法。
* 本方法把key作为参数key,所有v作为迭代器作为values。
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
// 遍历一组迭代器
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
执行类:
package cn.adoredu.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 程序运行的主类,封装程序执行的信息
*/
public class WordCountDriver {
public static void main(String[] args) throws Exception {
// 通过Job封装本次mr执行的信息
Configuration conf = new Configuration();
Job job = Job.getInstance();
// 指定运行主类
job.setJarByClass(WordCountDriver.class);
// 指定mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 指定mapper阶段的输出k/v类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 指定最终输出的k/v类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 指定输入和输出数据位置
FileInputFormat.setInputPaths(job, "/wordcount/input");
FileOutputFormat.setOutputPath(job, new Path("/wordcount/output"));
// 提交
// job.submit();
boolean res = job.waitForCompletion(true); // 使用该方法可以打印执行日志
System.exit(res?0:1);
}
}
集群运行:将mr程序交给yarn集群,分发到很多节点并发执行。
首先在hdfs上创建对应目录(注意输出目录不能提前创建,否则报错):
$: hadoop fs -mkdir -p /wordcount/input
编写测试文件并上传:
$: hadoop fs -put 1.txt 2.txt /wordcount/input
将程序使用mvn package打包为jar包,上传(至任意节点)并执行:
gp@node-1:~$ hadoop jar example-hdfs-1.0-SNAPSHOT.jar cn.adoredu.mapreduce.WordCountDriver
2020-04-15 15:03:12,212 INFO client.RMProxy: Connecting to ResourceManager at node-1/192.168.220.31:8032
2020-04-15 15:03:13,712 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2020-04-15 15:03:13,866 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/gp/.staging/job_1586744133402_0001
2020-04-15 15:03:14,181 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-04-15 15:03:14,692 INFO input.FileInputFormat: Total input files to process : 2
2020-04-15 15:03:14,791 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-04-15 15:03:15,053 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-04-15 15:03:15,093 INFO mapreduce.JobSubmitter: number of splits:2
2020-04-15 15:03:16,348 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2020-04-15 15:03:16,424 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1586744133402_0001
2020-04-15 15:03:16,424 INFO mapreduce.JobSubmitter: Executing with tokens: []
2020-04-15 15:03:16,936 INFO conf.Configuration: resource-types.xml not found
2020-04-15 15:03:16,936 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2020-04-15 15:03:18,133 INFO impl.YarnClientImpl: Submitted application application_1586744133402_0001
2020-04-15 15:03:18,404 INFO mapreduce.Job: The url to track the job: http://node-1:8088/proxy/application_1586744133402_0001/
2020-04-15 15:03:18,406 INFO mapreduce.Job: Running job: job_1586744133402_0001
2020-04-15 15:03:38,535 INFO mapreduce.Job: Job job_1586744133402_0001 running in uber mode : false
2020-04-15 15:03:38,538 INFO mapreduce.Job: map 0% reduce 0%
2020-04-15 15:03:47,677 INFO mapreduce.Job: map 50% reduce 0%
2020-04-15 15:04:01,863 INFO mapreduce.Job: map 100% reduce 0%
2020-04-15 15:04:04,921 INFO mapreduce.Job: map 100% reduce 100%
2020-04-15 15:04:04,957 INFO mapreduce.Job: Job job_1586744133402_0001 completed successfully
2020-04-15 15:04:05,171 INFO mapreduce.Job: Counters: 55
File System Counters
FILE: Number of bytes read=198
FILE: Number of bytes written=678704
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=306
HDFS: Number of bytes written=65
HDFS: Number of read operations=11
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
HDFS: Number of bytes read erasure-coded=0
Job Counters
Killed map tasks=1
Launched map tasks=3
Launched reduce tasks=1
Data-local map tasks=3
Total time spent by all maps in occupied slots (ms)=27618
Total time spent by all reduces in occupied slots (ms)=13564
Total time spent by all map tasks (ms)=27618
Total time spent by all reduce tasks (ms)=13564
Total vcore-milliseconds taken by all map tasks=27618
Total vcore-milliseconds taken by all reduce tasks=13564
Total megabyte-milliseconds taken by all map tasks=28280832
Total megabyte-milliseconds taken by all reduce tasks=13889536
Map-Reduce Framework
Map input records=5
Map output records=16
Map output bytes=160
Map output materialized bytes=204
Input split bytes=210
Combine input records=0
Combine output records=0
Reduce input groups=8
Reduce shuffle bytes=204
Reduce input records=16
Reduce output records=8
Spilled Records=32
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=431
CPU time spent (ms)=3380
Physical memory (bytes) snapshot=501583872
Virtual memory (bytes) snapshot=7798652928
Total committed heap usage (bytes)=307437568
Peak Map Physical memory (bytes)=212062208
Peak Map Virtual memory (bytes)=2597306368
Peak Reduce Physical memory (bytes)=96784384
Peak Reduce Virtual memory (bytes)=2604040192
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=96
File Output Format Counters
Bytes Written=65
gp@node-1:~$
查看结果(在hdfs页面或终端):
part-r-00000:
hadoop 1
hello 2
java 3
python 2
react 2
scala 2
spark 2
world 2
可以看到,执行完成后,1.txt和2.txt中单词总次数输出成功。其中_SUCCESS文件为空文件,表示程序运行成功。
本地运行:mr程序还可以提交给LocalJobRunner在本地以单线程的方式运行。该方式方便调试业务逻辑。数据可以使用本地或hdfs。
修改WordCountDriver类:
package cn.adoredu.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* 程序运行的主类,封装程序执行的信息
*/
public class WordCountDriver {
public static void main(String[] args) throws Exception {
// 通过Job封装本次mr执行的信息
Configuration conf = new Configuration();
// 是否本地执行取决于该配置信息,值为local时表示本地执行
conf.set("mapreduce.framework.name", "local"); // 实际上该配置可以省略,因为mapred-defalut.xml中默认就是local
Job job = Job.getInstance();
// 指定运行主类
job.setJarByClass(WordCountDriver.class);
// 指定mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 指定mapper阶段的输出k/v类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 指定最终输出的k/v类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 指定输入和输出数据位置
// 本地执行,使用本地fs
FileInputFormat.setInputPaths(job, "/Users/gp/Desktop/tmp/input");
FileOutputFormat.setOutputPath(job, new Path("/Users/gp/Desktop/tmp/output"));
// 提交
// job.submit();
boolean res = job.waitForCompletion(true); // 使用该方法可以打印执行日志
System.exit(res?0:1);
}
}
添加log4j.properties以查看日志,直接执行程序即可。
4.6 MapReduce数据分区
默认情况下,reduceTask个数为1,此时结果文件只有part-r-00000。通过job.setNumReduceTasks(3); 可以设置reduceTask个数,设置reduceTask个数后,结果会被划分到不同文件中,结果文件个数与reduceTask个数相同。
MapReduce的默认分区规则是根据map输出key的哈希值取模:
package org.apache.hadoop.mapred.lib;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.mapred.Partitioner;
import org.apache.hadoop.mapred.JobConf;
/**
* Partition keys by their {@link Object#hashCode()}.
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public void configure(JobConf job) {}
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
// & Integer.MAX_VALUE为了保证为正数。
4.7 MapReduce序列化
为能够在进程间传递对象或持久化对象,需要能够将对象序列号成字节流。相反地,若将接收到或从磁盘读取的字节流转化为对象,则要反序列化。
Java中序列化接口Serializable是一个重量级序列化框架,不便于在网络中高效传输,hadoop提供一套高效精简的序列化机制Writable:
public interface Writable {
void write(DataOutput out) throws IOException;
void readFields(DataInput in) throws IOException;
}
需求一:假设有文件格式如下,现要统计每个用户所耗费的总上行流量、下行流量和总流量。
// 格式形如:
1587087196 15412349850 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
时间戳 \t手机号 \t... 上行流量 下行流量 状态码
...
可以明确的是,mapper后结果key为手机号,若value为字符串拼接,后面分隔解析可以完成需求,但编码略显繁琐。这里可以通过定义一个序列化类,封装对应属性,将数据操作转化为对象属性操作,通过对象的网络传输完成功能。
定义Bean:
package cn.adoredu.flowsum;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FlowBean implements Writable {
private long upFlow;
private long downFlow;
private long sumFlow;
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
// 序列化方法
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
// 反序列化方法。注意反序列化时一定要和序列化时顺序一致
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readLong();
this.downFlow = in.readLong();
this.sumFlow = in.readLong();
}
}
Mapper:
package cn.adoredu.flowsum;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
// 提前定义,以免每次map都要新创建对象
Text k = new Text();
FlowBean flowBean = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
String phoneNum = fields[1];
long upFlow = Long.parseLong(fields[fields.length - 3]);
long downFlow = Long.parseLong(fields[fields.length - 2]);
k.set(phoneNum);
flowBean.set(upFlow, downFlow);
context.write(k, flowBean);
}
}
Reducer:
package cn.adoredu.flowsum;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class FlowReducer extends Reducer<Text, FlowBean, Text, FlowBean> {
FlowBean flowBean = new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
long upFlowCount = 0;
long downFlowCount = 0;
for (FlowBean flowBean : values) {
upFlowCount += flowBean.getUpFlow();
downFlowCount += flowBean.getDownFlow();
}
flowBean.set(upFlowCount, downFlowCount);
context.write(key, flowBean);
}
}
Driver:
package cn.adoredu.flowsum;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowSumDriver {
public static void main(String[] args) throws Exception {
// 通过Job封装本次mr执行的信息
Configuration conf = new Configuration();
// 是否本地执行取决于该配置信息,值为local时表示本地执行
conf.set("mapreduce.framework.name", "local"); // 实际上该配置可以省略,因为mapred-defalut.xml中默认就是local
Job job = Job.getInstance();
// 指定运行主类
job.setJarByClass(FlowSumDriver.class);
// 指定mapper和reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
// 指定mapper阶段的输出k/v类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
// 指定最终输出的k/v类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 指定输入和输出数据位置
// 本地执行,使用本地fs
FileInputFormat.setInputPaths(job, "/Users/gp/Desktop/tmp/flowsum/input");
FileOutputFormat.setOutputPath(job, new Path("/Users/gp/Desktop/tmp/flowsum/output"));
// 提交
// job.submit();
boolean res = job.waitForCompletion(true); // 使用该方法可以打印执行日志
System.exit(res?0:1);
}
}
需求二:将上述结果按总流量倒序排序。
要实现排序,我们可以将要排序的字段设置为key。这里由于数据封装,使用bean作为key。
在MapReduce中,如果要将自定义bean放在key传输,还要将bean实现Comparable接口,因为处理数据存在对key进行排序的过程。为方便起见,Hadoop提供WritableComparable接口:
package org.apache.hadoop.io;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
@InterfaceAudience.Public
@InterfaceStability.Stable
public interface WritableComparable<T> extends Writable, Comparable<T> {
}
修改bean:
package cn.adoredu.flowsum;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FlowBean implements WritableComparable<FlowBean> {
private long upFlow;
private long downFlow;
private long sumFlow;
public FlowBean() {
}
public FlowBean(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
public void set(long upFlow, long downFlow) {
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow + downFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" + sumFlow;
}
// 序列化方法
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
// 反序列化方法。注意反序列化时一定要和序列化时顺序一致
public void readFields(DataInput in) throws IOException {
this.upFlow = in.readLong();
this.downFlow = in.readLong();
this.sumFlow = in.readLong();
}
// 为了实现倒序
public int compareTo(FlowBean o) {
return sumFlow>o.getSumFlow()?-1:1;
}
}
实现:
package cn.adoredu.flowsum;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowSumSort {
public static class FlowSumSortMapper extends Mapper<LongWritable, Text, FlowBean, Text> {
// 提前定义,以免每次map都要新创建对象
Text v = new Text();
FlowBean k = new FlowBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
String phoneNum = fields[1];
long upFlow = Long.parseLong(fields[fields.length - 3]);
long downFlow = Long.parseLong(fields[fields.length - 2]);
v.set(phoneNum);
k.set(upFlow, downFlow);
context.write(k, v); // 输出时kv和上次相反
}
}
public static class FlowSumSortReducer extends Reducer<FlowBean, Text, Text, FlowBean> {
@Override
protected void reduce(FlowBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
context.write(values.iterator().next(), key); // reducer只作对调后输出
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 通过Job封装本次mr执行的信息
Configuration conf = new Configuration();
// 是否本地执行取决于该配置信息,值为local时表示本地执行
conf.set("mapreduce.framework.name", "local"); // 实际上该配置可以省略,因为mapred-defalut.xml中默认就是local
Job job = Job.getInstance();
// 指定运行主类
job.setJarByClass(FlowSumSort.class);
// 指定mapper和reducer
job.setMapperClass(FlowSumSortMapper.class);
job.setReducerClass(FlowSumSortReducer.class);
// 指定mapper阶段的输出k/v类型
job.setMapOutputKeyClass(FlowBean.class);
job.setMapOutputValueClass(Text.class);
// 指定最终输出的k/v类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 指定输入和输出数据位置
// 本地执行,使用本地fs
FileInputFormat.setInputPaths(job, "/Users/gp/Desktop/tmp/flowsum/output");
FileOutputFormat.setOutputPath(job, new Path("/Users/gp/Desktop/tmp/flowsum/outputsort"));
// 提交
// job.submit();
boolean res = job.waitForCompletion(true); // 使用该方法可以打印执行日志
System.exit(res?0:1);
}
}
需求三:将手机归属地不同,将结果划分到不同文件中。
自定义分区规则(要继承Partitioner类):
package cn.adoredu.flowsum.partitioner;
import cn.adoredu.flowsum.FlowBean;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
import java.util.HashMap;
public class ProvincePartitioner extends Partitioner<Text, FlowBean> {
public static HashMap<String, Integer> provinceMap = new HashMap<String, Integer>();
// 模拟省份划分规则
static {
provinceMap.put("131", 0);
provinceMap.put("132", 1);
}
public int getPartition(Text text, FlowBean flowBean, int numPartitions) {
Integer code = provinceMap.get(text.toString().substring(0, 3));
if (code != null) {
return code;
}
return 2;
}
}
在driver中设置分区类:
// ...
job.setNumReduceTasks(3);
// 设置分区规则
job.setPartitionerClass(ProvincePartitioner.class);
// ...
注意:分区个数要与reduceTask个数相同。如果分区个数小于reduceTask个数,会有空文件。而如果分区个数大于reduceTask个数,则程序报错。
4.8 Combiner
Combiner是map阶段后reduce阶段前的局部聚合组件,运行在每个maptask节点上,其目的是为了减少map和reduce节点之间数据传输量,以提高网络IO性能。Combiner组件的父类就是reducer。
比如WordCount案例中,如果某个maptask后结果为多个相同的<”Hello”, 1>,多跳数据传输到reduce比较消耗资源,而使用combiner可以先将多个<”Hello, 1”>合并为一个<”Hello”, n>。
使用:在WordCountDriver类中只需添加:
job.setCombinerClass(WordCountReducer.class);